
I Asked 3 Models 'What is MCP?' — Then I Fixed the Data
I asked three language models the same question: “What is MCP?”
All three had the same knowledge base — 24 blog posts from this site. The same retrieval pipeline. The same correct article sitting right there in the search results.
All three got it wrong.
phi3:mini said “Machine-Comprehensible Protocols.” mistral said “Model-driven Cloud Platform.” Even gpt-4.1-mini — a cloud model running on GPU-accelerated Azure infrastructure — said “Modular Capability Protocol.”
Three models. Three different wrong answers. The correct answer — Model Context Protocol — was in the source article the whole time.
I honestly didn’t expect that. The cloud model was supposed to be the control — the one that “just works.” When it hallucinated too, I sat there staring at the screen for a minute thinking okay, so what is actually going on here?
Then I swapped the retrieval engine. Same models, same documents, same question. And all three got it right.
Watch the experiment in 2 minutes — same question, same models, two very different outcomes:
This whole thing started as me playing around with a Raspberry Pi 5 — a new toy in my lab, nothing serious. I wanted to see if I could run a RAG system locally, just for fun. It ended up sweating through this experiment and teaching me something I didn’t expect about how grounding actually works. I hope it clarifies things for you too.
Contents
- The Setup
- Act 1: ChromaDB — Everyone Gets It Wrong
- Act 2: Azure AI Search — Everyone Gets It Right
- What Changed
- Why Did They Lie?
- Security Trimming Doesn’t Care About Your Model
- The MCP Irony
- What This Means in Practice
- For Enterprise & Business Architects
- The Experiment — Screenshots
The Setup
I built a RAG (Retrieval-Augmented Generation) system on a Raspberry Pi 5. The architecture:
- Documents: 24 blog posts from ntit.ai
- Retrieval: Swappable — ChromaDB (local on the Pi) or Azure AI Search (cloud)
- LLM: Swappable —
phi3:mini(3.8B),mistral(7B) via Ollama on the Pi, orgpt-4.1-minivia Azure OpenAI - Security trimming: Each chunk is tagged with Entra-style security groups. Users only see what their groups allow.
The RAG pipeline is the same regardless of configuration:
- User asks a question
- Retrieval engine finds the most relevant chunks
- Chunks are filtered by the user’s security groups
- The chunks + question are sent to the LLM
- The LLM generates an answer grounded in the retrieved content
The experiment: hold the question constant, hold the documents constant, and change two things — the retrieval engine and the model. See what breaks.
Act 1: ChromaDB — Everyone Gets It Wrong
ChromaDB runs locally on the Pi’s NVMe drive. It stores 378 chunks created from the 24 blog posts using fixed 500-character splits with 50-character overlap. The embedding model (all-MiniLM-L6-v2) also runs locally — no API calls, no cloud, fully offline.
The question: “What is MCP?”
The correct answer: MCP stands for Model Context Protocol, an open standard by Anthropic that lets AI systems connect to external tools and data sources through a unified interface. I’ve written about it — the article was in the knowledge base, indexed, chunked, and ready to be found.
Here’s what happened:
phi3:mini (3.8B)
“MCP stands for Machine-Comprehensible Protocols”
Fast, confident, completely wrong. Not just the acronym — the entire concept was fabricated. It went off about Microsoft’s Digital Twins ecosystem and Codeplex, of all things. And here’s the fun part: I asked the same question multiple times and got a different wrong answer each time. It wasn’t even consistently wrong — just creatively wrong in a new way every time.
mistral (7B)
“MCP stands for Model-driven Cloud Platform”
Wrong acronym — but wait. The description was actually accurate. It talked about a “standardized tool interface for AI agents,” which is exactly what MCP does. So mistral clearly understood the concept from the retrieved chunks. It just… made up the name. Close enough to be frustrating.
gpt-4.1-mini (Cloud)
“MCP stands for Modular Capability Protocol”
Yeah, I didn’t see this one coming. The cloud model — running on actual GPU infrastructure in Azure — also got it wrong. It described MCP’s purpose well enough, but the name? Nope. So much for “just throw a bigger model at it.”
Act 1 Results
| phi3:mini (3.8B) | mistral (7B) | gpt-4.1-mini (Cloud) | |
|---|---|---|---|
| Answer | ”Machine-Comprehensible Protocols" | "Model-driven Cloud Platform" | "Modular Capability Protocol” |
| Concept | Wrong | Correct | Correct |
| Name | Wrong | Wrong | Wrong |
| Match score | 48% | 47% | 44% |
0 for 3.
At this point, I thought I understood the problem. The source article uses “MCP” throughout but never spells out “Model Context Protocol.” Classic grounding gap — the fact just wasn’t in the chunks. Made sense. Case closed.
Except it wasn’t. The fact was there. It was just buried under so much noise that no model could dig it out.
Act 2: Azure AI Search — Everyone Gets It Right
I uploaded the same 24 blog posts to Azure Blob Storage and created an Azure AI Search index. Same documents. Same content. But Azure AI Search handles the ingestion differently — it cracks the documents, strips HTML, chunks intelligently, and indexes with hybrid search (vector similarity + BM25 keyword matching) and semantic reranking on top.
The result: 116 chunks instead of 378. Fewer chunks, but each one is clean, dense text.
I added a toggle to the UI so I could switch between ChromaDB and AI Search at runtime, then asked the same question with the same three models.
phi3:mini (3.8B)
“MCP stands for Model Context Protocol”
I actually laughed out loud. The same 3.8B model that made up a different wrong answer every time with ChromaDB — first try, got it right.
mistral (7B)
“MCP stands for Model Context Protocol”
Correct. Clean answer, accurate description.
gpt-4.1-mini (Cloud)
“MCP stands for Model Context Protocol”
Correct.
Act 2 Results
| phi3:mini (3.8B) | mistral (7B) | gpt-4.1-mini (Cloud) | |
|---|---|---|---|
| Answer | ”Model Context Protocol" | "Model Context Protocol" | "Model Context Protocol” |
| Match score | 68% | 68% | 68% |
3 for 3.
What Changed
Not the models. ✓ Not the documents. ✓ Not the question. ✓

The only thing that changed was
how the data was prepared
before the model saw it.
Here’s what a ChromaDB chunk looked like — this is what the model was actually reading:
rgba(255,255,255,0.08);border:1.5px dashed rgba(255,255,255,0.35);
display:inline-block;"></span> External</span> </div>
Compare patterns 2 and 3 — the only difference is **Plugins** swapped for...That’s CSS. Inline styles. Broken HTML tags. I wouldn’t be able to extract meaning from this either, honestly. And I was asking a 3.8B parameter model to make sense of it.
Here’s the same document as an AI Search chunk:
title: "MCP + Agents: What They Are, When to Combine Them"
description: "MCP is how tools expose capabilities. Agents are how AI
decides what to do. They're complementary, not competing..."Clean frontmatter. Clear sentences. The model reads it like a human would.
The difference comes down to what happened between “document” and “chunk”:
| ChromaDB | Azure AI Search | |
|---|---|---|
| Document cracking | None — raw markdown with embedded HTML | Strips HTML, extracts clean text |
| Chunking | Fixed 500-char splits | Semantic boundaries |
| Search | Vector similarity only | Hybrid: vector + BM25 keywords |
| Reranking | None | Semantic reranking |
| Chunks | 378 (noisy, lots of filler) | 116 (dense, clean) |
| Match scores | 44-48% | 68% |
| Result | 0/3 correct | 3/3 correct |
The retrieval engine found the right article both times. But ChromaDB served it as CSS soup and AI Search served it as clean text. That’s not a model problem. That’s a data pipeline problem.
Why Did They Lie?
The models didn’t lie. They did exactly what they’re designed to do — predict the next most likely token.
Language models don’t know things. They predict what word comes next based on patterns from training plus whatever context you provide. When the context is clear and the answer is in it, they get it right. When the context is noisy and the signal is buried, they fill the gap with something plausible.
“Machine-Comprehensible Protocols” sounds like it could be a real thing, right? “Modular Capability Protocol” follows the pattern of technical acronyms perfectly. These models aren’t broken — they’re doing exactly what we told them to do, but on garbage input. Garbage in, garbage out. The oldest rule in computing, showing up in the newest technology.
This is hallucination by design, not by defect. The model’s job is to produce plausible text. When it can’t extract the right answer from the context it was given, it constructs the most plausible alternative. Feed it clean context, and the right answer becomes the most plausible continuation.
The experiment proved this from both directions:
- Noisy chunks → all three models hallucinated (including the cloud frontier model)
- Clean chunks → all three models got it right (including the tiny 3.8B model on a Pi)
Security Trimming Doesn’t Care About Your Model
The RAG system includes identity-aware security trimming. Each chunk is tagged with security groups — both in ChromaDB (metadata filter) and Azure AI Search (OData filter on allowed_groups). When a user asks a question, only chunks matching their group membership are returned.
I tested this across all three models and both retrieval engines:
- Ameed (all groups): Gets the MCP article because it’s tagged for SG-AI-Engineering and SG-Architecture
- External Guest (SG-Public only): Gets a completely different answer — the system returns only publicly-tagged content
The security trimming worked identically everywhere — across phi3:mini, mistral, gpt-4.1-mini, ChromaDB, and AI Search. The guest user never saw restricted content. This makes sense: the filtering happens at the retrieval layer, before the LLM ever sees the chunks. The model can’t hallucinate content it was never given.
Your security boundary is independent of your AI model and your search engine. Swap models, swap retrieval backends, run everything locally or fully in the cloud — the access control doesn’t change because it’s enforced at the data layer, not the generation layer.
I covered the full implementation of security trimming in Azure AI Search in a previous post.
The MCP Irony
I only realized this after the experiment, but there’s a fun irony here.
The question I asked — “What is MCP?” — is about Model Context Protocol, the standard that lets AI systems connect to external tools and data sources. The whole point of MCP is to give models access to real, grounded information instead of relying on their training data.
The models that hallucinated were doing exactly what MCP is designed to prevent — reaching into unreliable training weights to fill a gap that better tooling could have closed. They had retrieved context from RAG, but when that context was noisy, they fell back on guessing.
This is the spectrum:
- Raw LLM: Brain in a jar. Predicts from training data. Hallucinates when gaps exist.
- LLM + bad RAG: Brain with a blurry library card. Finds the right book but reads through smudged glasses.
- LLM + good RAG: Brain with a clean library card. Reads the right content clearly.
- LLM + good RAG + Tools (Agent): Brain with a library card, hands, and a phone. Can look things up, verify, and loop until the answer is right.
In my experiment, the jump from “bad RAG” to “good RAG” — just swapping ChromaDB’s raw HTML chunks for AI Search’s clean text — moved every model from wrong to right. No model upgrade. No bigger GPU. No extra spend. Just better data prep.
What This Means in Practice
Invest in your data pipeline before upgrading your model
If I take one thing from this experiment, it’s this. Every model I tested — from a tiny 3.8B on a Raspberry Pi to a cloud model on Azure — hallucinated with noisy chunks and succeeded with clean ones. If your RAG system is giving you unreliable answers, look at your ingestion pipeline before blaming the model.
Specifically:
- Strip HTML and markup before chunking. If your source documents contain embedded styling, the model is wasting context window on CSS.
- Use semantic chunking instead of fixed-size splits. A chunk that cuts a sentence in half is worse than a slightly larger chunk that preserves meaning.
- Consider hybrid search. Vector similarity alone can miss keyword-level matches. BM25 + vector + semantic reranking catches what pure vector search doesn’t.
Security trimming belongs at the data layer
I tested security trimming across six configurations (3 models x 2 search engines) and it worked identically every time. The architecture is simple: tag chunks with groups, filter at retrieval, and the LLM never sees what the user shouldn’t see. This holds regardless of which model or search engine you use.
Hallucination is a data quality signal
When a RAG system hallucinates, the first instinct is usually “we need a better model.” I had that same instinct. This experiment showed me it’s often the wrong lever to pull. A hallucinating model might actually be telling you something useful — that your chunks are noisy, your chunking is too agressive, or your search isn’t surfacing the right context.
Before switching to a larger model, try:
- Inspecting the actual chunks your model receives (not just which documents were retrieved)
- Checking for HTML/markup noise in the chunks
- Comparing match scores — are they below 50%? Your search might be returning low-relevance content
- Testing with a document cracking pipeline (Azure AI Search, Unstructured.io, or even a simple HTML strip in your ingestion code)
The full experiment matrix
| Model | ChromaDB (378 chunks) | Azure AI Search (116 chunks) |
|---|---|---|
| phi3:mini (3.8B, local) | “Machine-Comprehensible Protocols” | Model Context Protocol |
| mistral (7B, local) | “Model-driven Cloud Platform” | Model Context Protocol |
| gpt-4.1-mini (cloud) | “Modular Capability Protocol” | Model Context Protocol |
0/3 → 3/3. Same models. Same docs. Different chunks.
For Enterprise & Business Architects
Garbage In, Garbage Out — the oldest rule in computing, and somehow still the one we keep re-learning.
Data quality used to be a reporting concern. Keep your data warehouse clean, your pipelines reliable, your dashboards accurate. That was the scope. But AI changes the equation. RAG is becoming one of the core patterns for grounding AI in your organization’s actual knowledge — across support, operations, engineering, compliance, you name it. And RAG is only as good as what it retrieves.
Whether you’re building agentic orchestrations, integrating tools through MCP, or wiring up any other AI topology — all of it depends on the quality of the underlying data estate. A model reading noisy, poorly structured documents is not that different from a person trying to make a decision based on a document that’s half CSS and half actual content. You might still produce an answer. It just won’t be the right one.
This experiment showed it concretely: a 3.8B model running on a Raspberry Pi got the right answer with clean chunks. A cloud model with orders of magnitude more compute got it wrong with noisy ones. The differentiator wasn’t the model. It wasn’t the infrastructure. It was how the data was prepared before the model ever saw it.
Maintaining a quality data estate is an AI readiness concern now — not just a BI one. The organizations that treat their knowledge base as a first-class asset will be the ones where AI actually delivers.
The Experiment — Screenshots
Click any thumbnail to see the full screenshot.
ChromaDB — Hallucinated
Azure AI Search — Correct
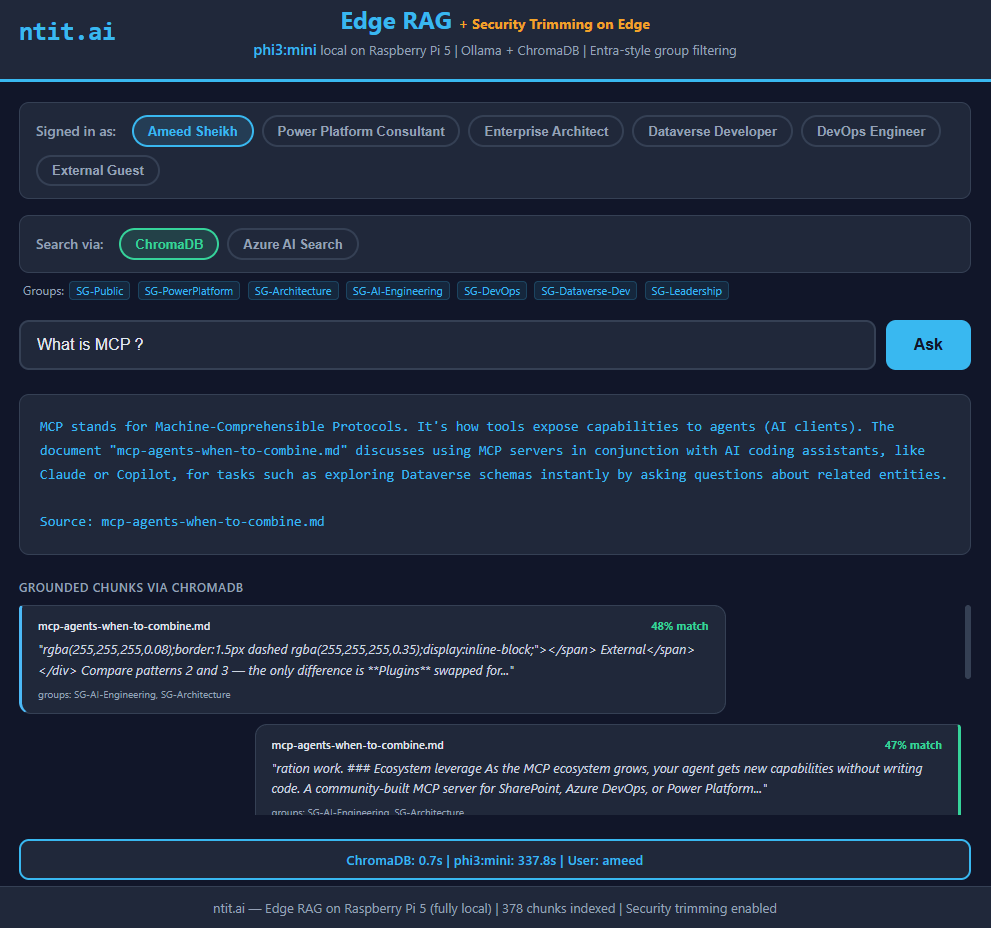
phi3:mini (3.8B) — "Machine-Comprehensible Protocols"
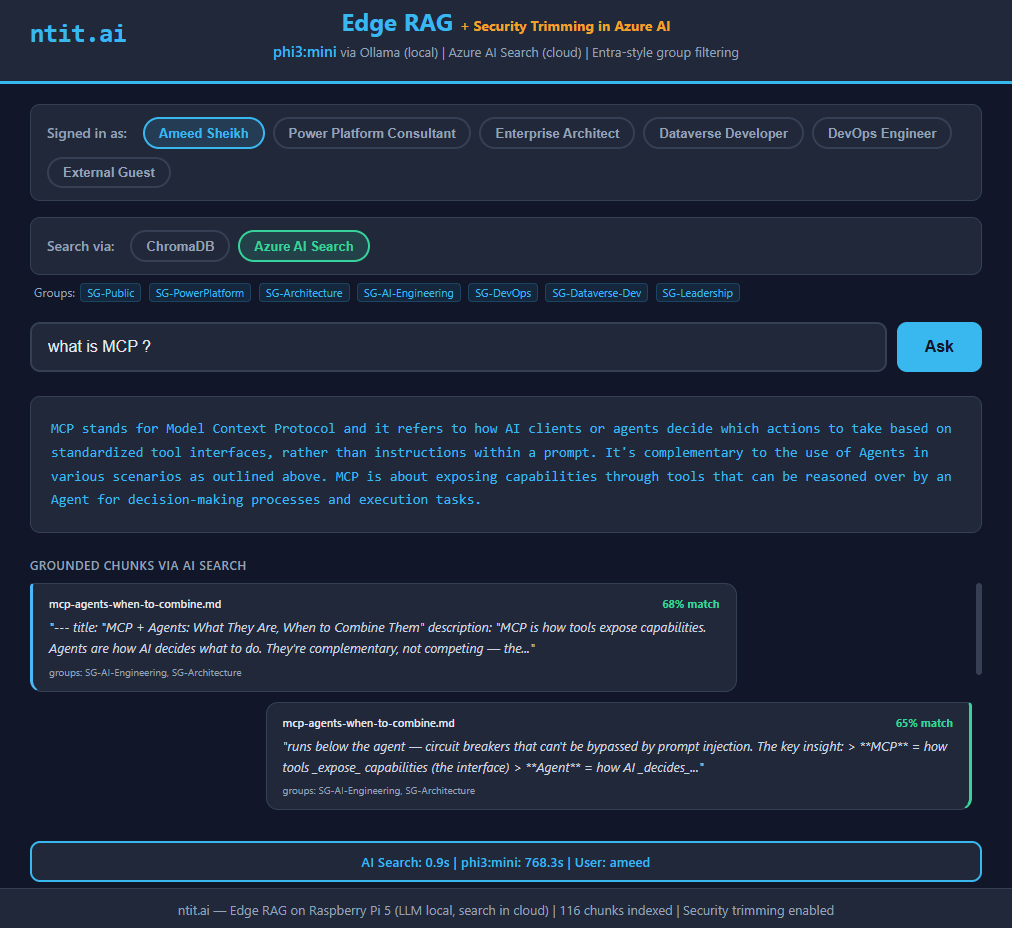
phi3:mini (3.8B) — "Model Context Protocol"
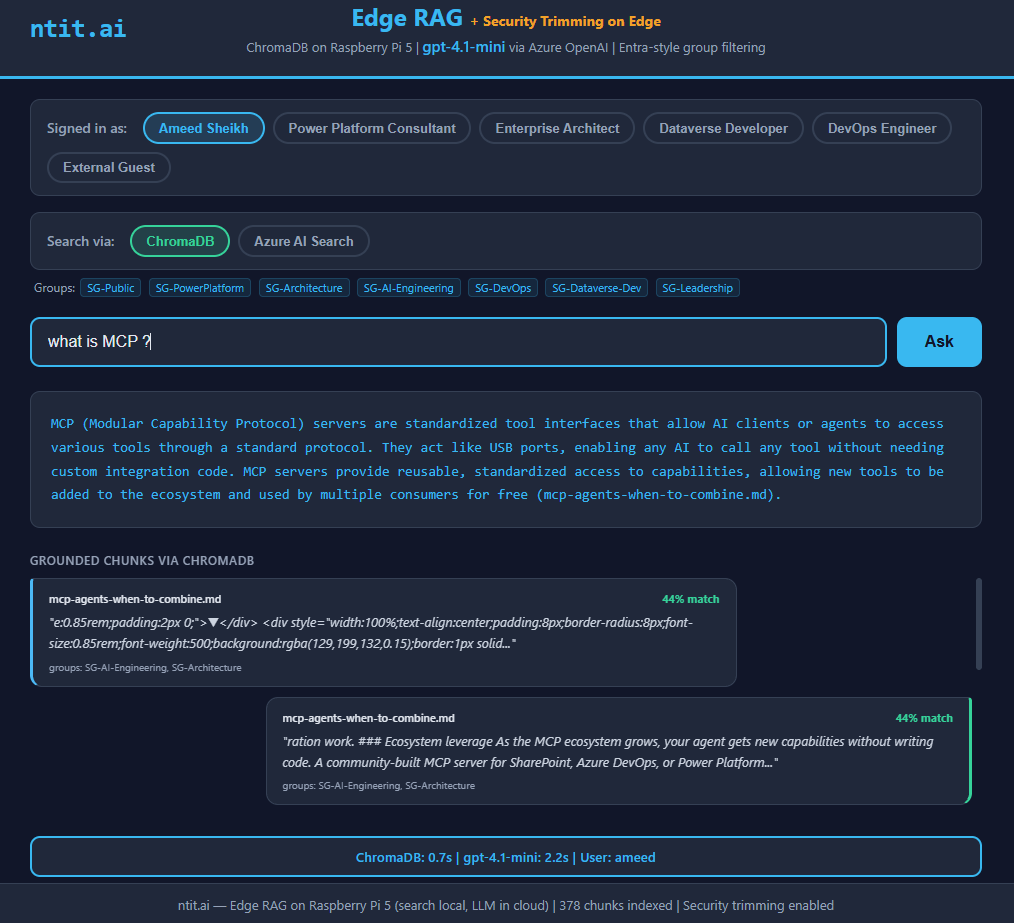
gpt-4.1-mini (cloud) — "Modular Capability Protocol"
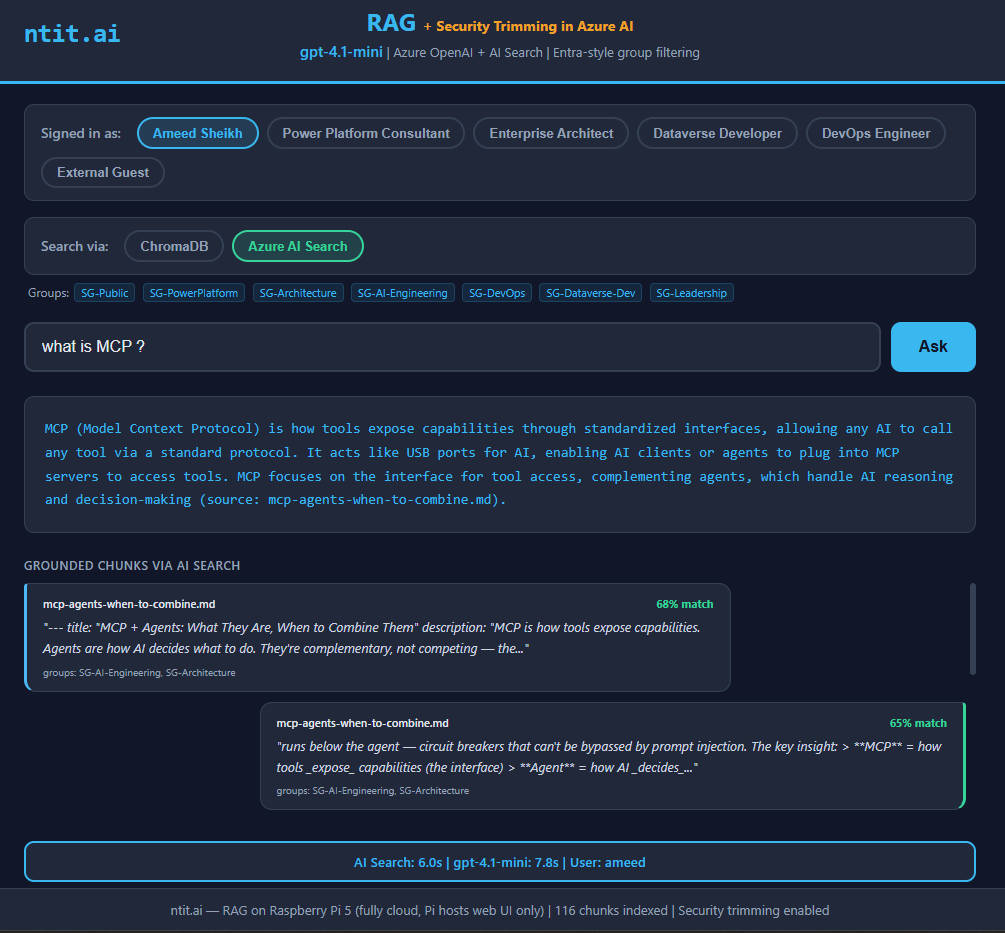
gpt-4.1-mini (cloud) — "Model Context Protocol"
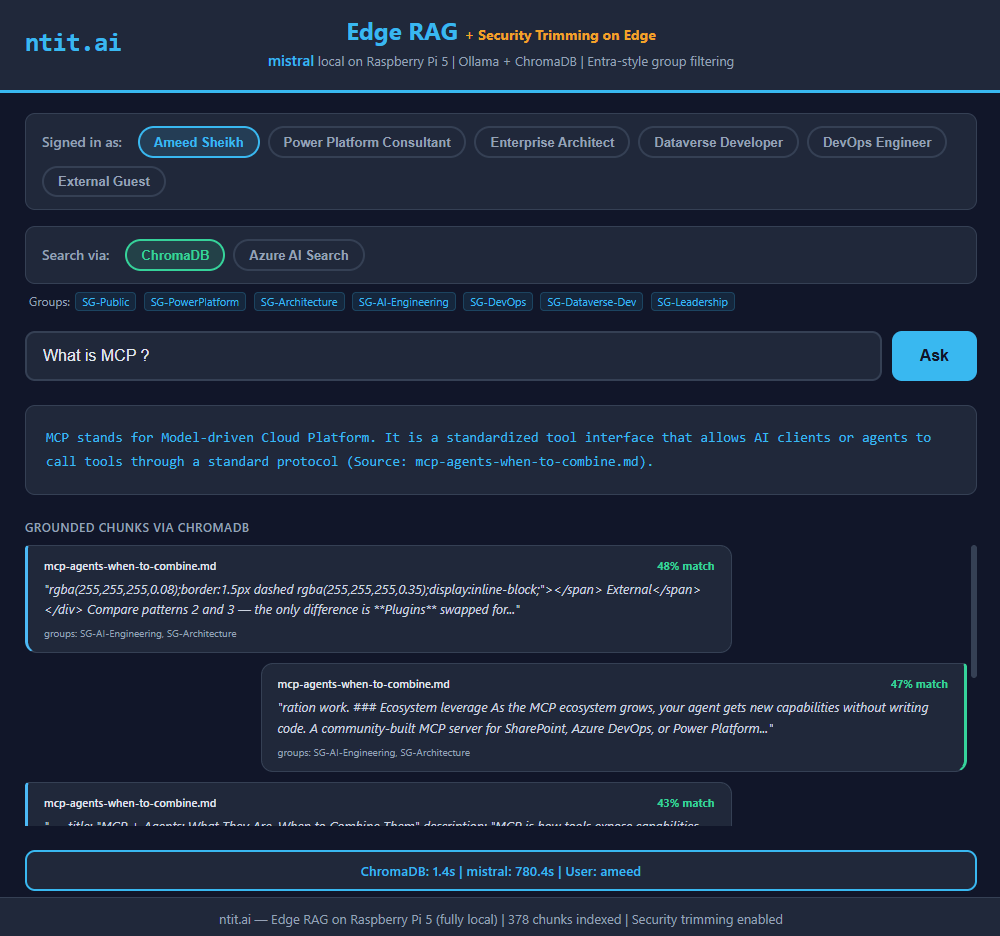
mistral (7B) — "Model-driven Cloud Platform"
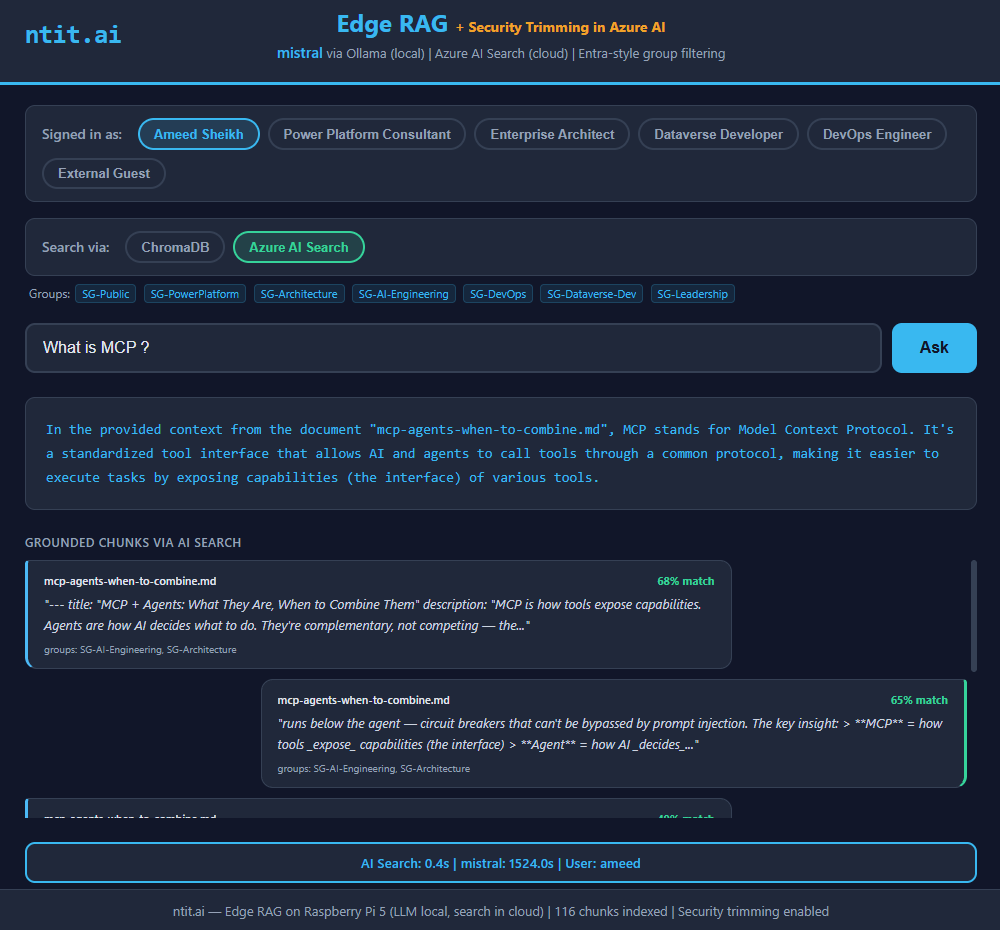
mistral (7B) — "Model Context Protocol"
Same models. Same question. Left column: noisy chunks. Right column: clean chunks.
Built on a Raspberry Pi 5 (16GB), Ollama, ChromaDB, Azure AI Search, Azure OpenAI (gpt-4.1-mini), and way too much coffee at 4am. The Pi ran hot, the models took their sweet time, and I probably should have gone to bed earlier. But I learned something I didn’t expect, and that’s worth a few lost hours of sleep.
#RAG #DataQuality #AI #EdgeAI #LLM #AzureAISearch #Hallucination #AIgineering #ProDev #NordTekIT